![A logo representing a calm, happy Sweden countryside village with only blue color palette [and has a minimalist and modern style] [incorporating elements of nature] [with a touch of Scandinavian design] [that reflects a sense of community]](https://raonstad.com/wp-content/uploads/2024/03/img-rsVXmvlyKd0umO7b2rMmaUnI.png)
프롬프트 엔지니어링 예시
프롬프트 엔지니어링 예시 관련 포스팅입니다.
이른바 깡통 LLM(Foundation Large language model)이 내가 원하는 맞춤형 답을 할 수 있도록 제어하는 방법입니다.
프롬프트 엔지니어링이란

프롬프트 엔지니어링이란 쉽게 말해 나만의 Chat GPT를 만드는 방법입니다.
생성형 AI를 우리가 처음부터 개발하고 데이터를 학습시켜 나만의 Chat GPT와 같은 프로그램을 만드는 일은 굉장히 어렵습니다.
그러나 요즘은 이른바 오픈 소스의 개발 방법이 보편화 되어 있고 연구의 결과물들을 한 곳에 모아 보관하는 서비스와 약간의 프로그래밍 지식과 생성형 AI에 대한 개념이 있다면 약간의 수고로 누구나 경험해 볼 수 있도록 도와주는 도구들이 너무 잘 되어 있습니다.
프롬프트 엔지니어링이란 이른바 올바른 답을 얻을 수 있도록 좋은 질문을 하는 방법이고 이것에 관련된 엔지니어링 측면의 접근법을 말합니다.
이 포스트는 허깅페이스의 인프라스트럭쳐를 사용하여 파이썬 노트북으로 프롬프트 엔지니어링을 해본 경험과 관련된 글입니다.
Machine Learning과 생성형 AI의 차이점(Generative AI)


이른바 일반적인 Machine Learning AI는 많은 패턴을 컴퓨터 프로그램에 학습시킨 후 임의의 값을 입력했을때, 이에 가장 근접한 답을 낼 수 있도록 하는 일입니다.
수학적으로 이야기 하면, 임의의 확률 분포를 계산할 수 있는 함수를 컴퓨터 프로그램으로 만들고 이 함수의 인자들(일반적으로 파라미터라고 이야기 합니다.)이 최적의 값으로 (가장 확률이 높은 값으로) 동작할 수 있도록 인자들의 값을 최적화 하는 일을 이야기 합니다.
이에 비해 생성형 AI는 (텍스트 기반으로 설명을 하면) 각 단어들의 뜻과 이 단어들이 글의 내부에 위치한 순서 및 조합에 대한 확률을 계산하고, 주어진 문장에 대해 답이 될 수 있는 단어들과 문장들의 조합을 가장 높은 확률이 되도록 조합하여 출력하는 프로그램을 말합니다.
일반적인 Machine Learning은 “예” 혹은 “아니오” 를 대답할 수 있는 반면, 생성형 AI는 가장 그럴싸한 컨텐트를 만들어 낼 수 있습니다.
기본 모델 (Foundation Model)이란
기본 모델이란 위에 설명한 것과 같이 최적의 조합을 만들어 내는 프로그램(알고리즘)과 최적의 조합을 만들어 내는 파라미터들의 모임을 이야기 합니다.
즉 기본적인 프로그램에 영어 사전과 문법책에 나오는 기본 문법만 가르켜 놓은 상태의 프로그램을 이야기 합니다.
프롬프트 엔지니어링 예시 실험 방법
프롬프트 엔지니어링 예시 를 위하여 사용한 재료들을 간단히 설명합니다.
사용할 라이브러리
사용할 라이브러리는 허깅페이스 사의 Transformer 라이브러리와 Tokenization 라이브러리를 사용합니다.
프로그래밍 언어는 파이썬, 그리고 실행환경은 구글 Colab의 파이썬 노트북을 사용합니다.
사용할 모델

구글의 “flan-t5-base” 모델을 사용합니다. 허깅페이스 사에서 지원되는 모델입니다.
구글에서 개발된 T5 모델의 향상된 버전으로, 다양한 영역에서 높은 수준의 성능을 제공합니다. 프롬프트 엔지니어링 작업에 대한 연구 및 채팅 및 대화 요약, 텍스트 분류등의 작업에 사용될 수 있습니다.
사용할 데이터 셋

knkarthick/dialogsum 데이터셋은 Dailydialog, DREAM, MuTual, 그리고 영어 말하기 연습 웹사이트와 같은 다양한 출처에서 가져온 대화를 포함한 포괄적인 대화 요약 데이터셋입니다.
학교, 직장, 쇼핑, 여가, 여행과 같은 다양한 주제 그리고 친구, 동료, 고객들간의 대화에 관한 데이터를 가지고 있어, 실생활에서 사용될 수 있는 대화와 이에 관한 요약을 제공합니다.
실험결과 분석
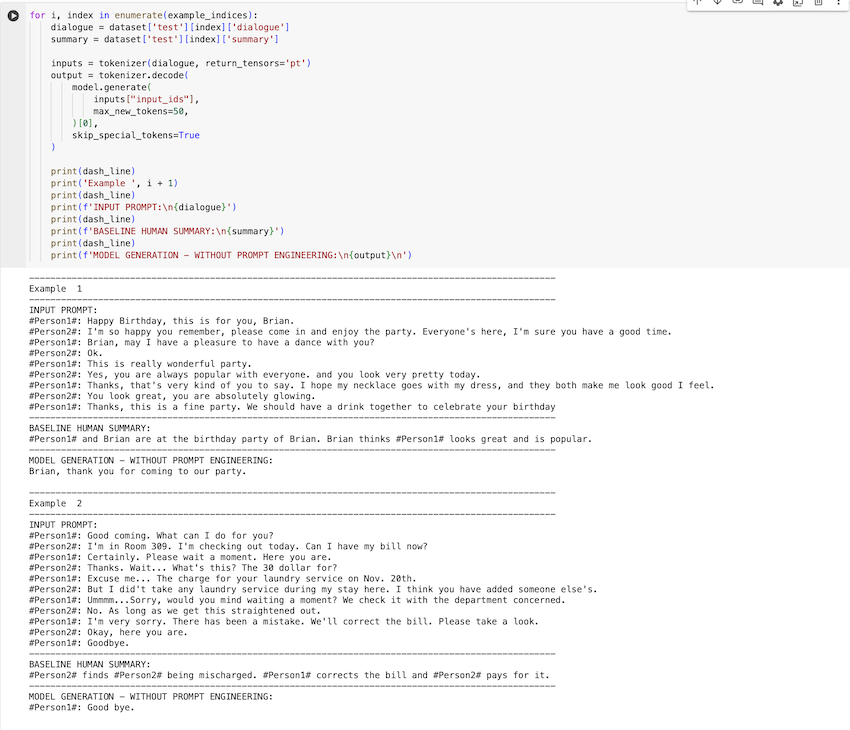
생성형 AI 출력에 아무런 조건도 걸지 않았을 때
for i, index in enumerate(example_indices):
dialogue = dataset['test'][index]['dialogue']
summary = dataset['test'][index]['summary']
prompt = f"""
Summarize the following conversation.
{dialogue}
Summary:
"""LLM에 어떠한 예도 주지 않고 단순히 “Summary”라는 단어만 주었을때의 결과입니다.
뭔가 답은 내고 내용도 틀리지는 않는데… 약간 우리가 원하는 결과는 아닙니다. “Summary”라는 단어가 Decoder부분의 실행에 영향을 준것으로 보입니다.
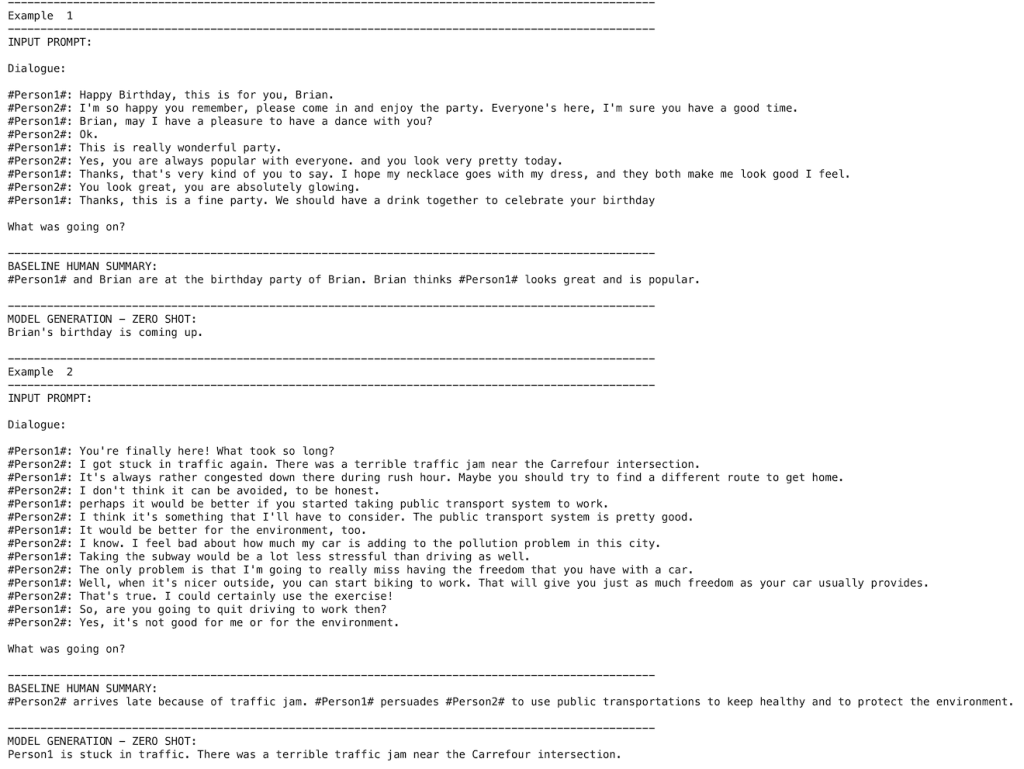
짧은 조건을 걸었을 때
prompt += f"""
Dialogue:
{dialogue}
What was going on?
{summary}
"""
dialogue = dataset['test'][example_index_to_summarize]['dialogue']
prompt += f"""
Dialogue:
{dialogue}
What was going on?
"""예문을 보여주고 구체적인 질문인 “What was going on?”이라는 문장을 프롬프트에 추가 하였습니다.
답변의 내용이 예로 든 요약에 어느정도 근접해 가는 것을 볼 수 있습니다.
강한 조건을 걸었을 때
Dialogue:
#Person1#: This Olympic park is so big!
#Person2#: Yes. Now we are in the Olympic stadium, the center of this park.
#Person1#: Splendid! When is it gonna be finished?
#Person2#: The whole stadium is to be finished this June.
#Person1#: How many seats are there in the stand?
#Person2#: Oh, there are 5000 seats in total.
#Person1#: I didn ' t know it would be so big!
#Person2#: It is! Look there, those are the tracks. And the jumping pit is over there.
#Person1#: Ah... I see. Hey, look the sign here, No climbing.
#Person2#: We put many signs with English translations for foreign visitors.
What was going on?
#Person1# is surprised at the Olympic Stadium'volume, capacity and interior setting to #Person1#.
Dialogue:
#Person1#: I've had it! I am done working for a company that is taking me nowhere!
#Person2#: So what are you gonna do? Just quit?
#Person1#: That's exactly what I am going to do! I have decided to create my own company! I am going to write up a business plan, get some investors and start working for myself!
#Person2#: Have you ever written up a business plan before?
#Person1#: Well, no, it can't be that hard! I mean, all you have to do is explain your business, how you are going to do things and that's it, right?
#Person2#: You couldn't be more wrong! A well written business plan will include an executive summary which highlights the idea of the business in two pages or less. Then you need to describe your company with information such as what type of legal structure it has, history, etc.
#Person1#: Well, that seems easy enough.
#Person2#: Wait, there is more! Then you need to introduce and describe your goods or services. What they are and how they are different from competitors? Then comes the hard part, a market analysis. You need to investigate and analyze hundreds of variables! You need to take into consideration socioeconomic factors from GDP per capita to how many children on average the population has! All this information is useful so that you can move on to your strategy and implementation stage, where you will describe in detail how you will actually execute your idea.
#Person1#: Geez. Is that all?
#Person2#: Almost, the most important piece of information for your investors will be the financial analysis. Here you will calculate and estimate sales, cash flow and profits. After all, people will want to know when they will begin to see a return on their investment!
#Person1#: Umm. I think I ' ll just stick to my old job and save myself all the hassle of trying to start up a business!
What was going on?
#Person1# wants to create a company and is going to write a business plan. #Person2# gives #Person1# suggestions on how to summarise business ideas, describe the service, differ from competitors and attract investment in a good business plan. #Person1# decides to stick to the old job.
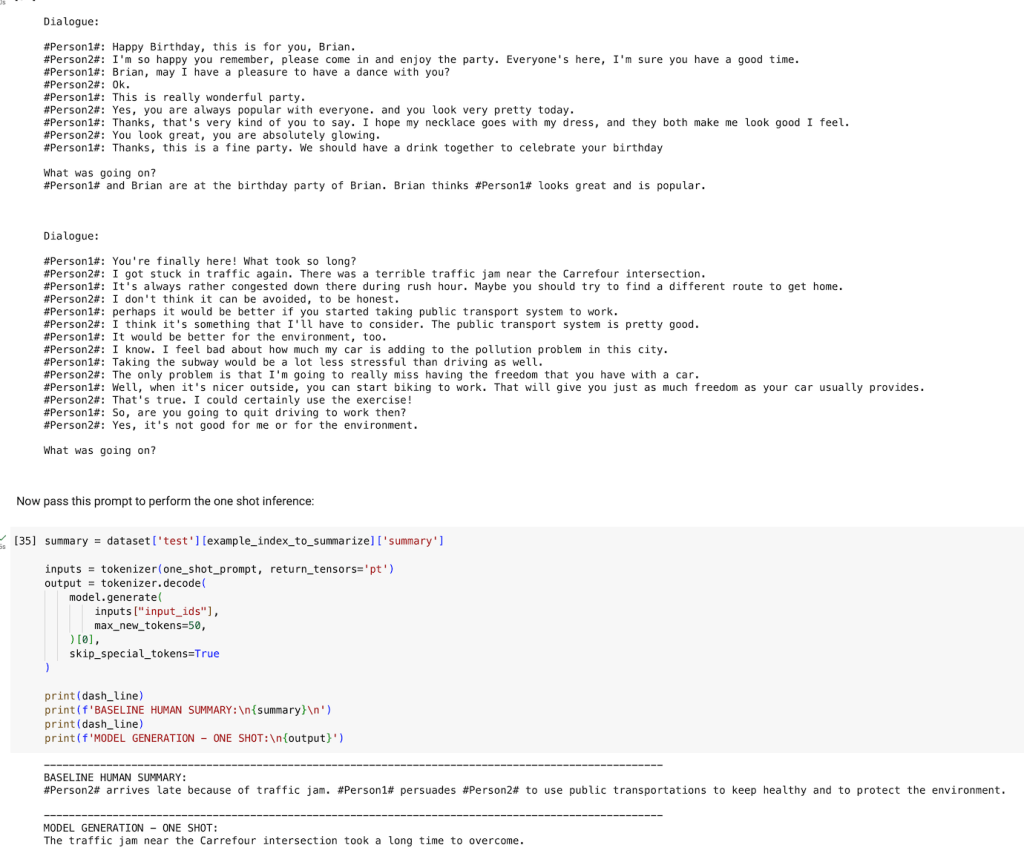
Dialogue:
#Person1#: You're finally here! What took so long?
#Person2#: I got stuck in traffic again. There was a terrible traffic jam near the Carrefour intersection.
#Person1#: It's always rather congested down there during rush hour. Maybe you should try to find a different route to get home.
#Person2#: I don't think it can be avoided, to be honest.
#Person1#: perhaps it would be better if you started taking public transport system to work.
#Person2#: I think it's something that I'll have to consider. The public transport system is pretty good.
#Person1#: It would be better for the environment, too.
#Person2#: I know. I feel bad about how much my car is adding to the pollution problem in this city.
#Person1#: Taking the subway would be a lot less stressful than driving as well.
#Person2#: The only problem is that I'm going to really miss having the freedom that you have with a car.
#Person1#: Well, when it's nicer outside, you can start biking to work. That will give you just as much freedom as your car usually provides.
#Person2#: That's true. I could certainly use the exercise!
#Person1#: So, are you going to quit driving to work then?
#Person2#: Yes, it's not good for me or for the environment.
What was going on?
이번에는 같은 질문에 대하여 예문을 3가지 종류를 주어 보겠습니다.

결론
위의 예에서와 같이 별도의 수정 없이도 우리가 LLM을 사용하여 얻고자 하는 작업이 단순하다면 몇가지의 비슷한 종류의 예문을 주고 처리를 하고자 하는 텍스트를 문제로 주면 어느정도 우리가 원하는 답에 근접해가는 모습을 보여 주고 있습니다.
결국 생성형 AI를 실제 업무에 적용하려 할 때 얼마만큼의 투자를 해야 하는지에 대한 결정은 우리가 풀어야 할 문제를 얼마나 정확히 파악하고 있느냐에 따라 간단한 방법으로도 원하는 결과를 얻을 수 있슴을 보여 줍니다.
여기에서 간단한 방법이라 했지만, 우리가 원하는 바를 얻기 위해서는 대상이 기계라고 할지라도 질문을 “잘” 해야 한다는 점이 중요한 포인트라 할 수 있겠습니다.
긴 글 읽어주셔서 감사합니다.





