![A logo representing a calm, happy Sweden countryside village with only blue color palette [and has a minimalist and modern style] [incorporating elements of nature] [with a touch of Scandinavian design] [that reflects a sense of community]](https://raonstad.com/wp-content/uploads/2024/03/img-rsVXmvlyKd0umO7b2rMmaUnI.png)
삼성 AI 두뇌 차세대 칩
삼성 AI 두뇌 차세대 칩.
삼성이 미래 사업에 선도적 위치를 탈환하기 위하여 새로운 AI 두뇌 역할을 하는 차세대 칩을 개발을 착수 했다는 소식이 보도 되었습니다.
이 새로운 개발 조직을 이끄는 수장은 구글에서 TPU를 개발한 경력을 가진 사람이라고 합니다.
따라서 삼성 AI 두뇌 차세대 칩 은 그것이 어떤 형태가 되었던간에 구글의 TPU에 기반 하거나, 적어도 비슷한 구조를 가진 제품일 가능성이 높습니다.
그러므로 구글에서 제공하는 TPU에 대한 이해는 향후 삼성 AI 두뇌 차세대 칩 이 어떤 형태로 발전 될 것이며 이것에 필요한 핵심 기술이 어떤 것이 될 지 가늠해 볼 수 있는 단초를 제공할 수 있다고 생각됩니다.
삼성 AI 두뇌 차세대 칩 과 비교 되는 구글의 TPU

TPU(Tensor Processing Unit)는 구글에서 맞춤 개발한 ASIC(Application-Specific Integrated Circuits) 칩입니다.
ASIC 칩은 사용자 맞춤형 반도체로서 옷으로 비교하자면 미리 정해진 신체 사이즈에 맞추어 재단되어지고 완성되어진 기성복을 사는 것이 아니라 우리 몸에 딱 맞는 정장을 맞추어 입는 맞춤복과 비슷하다 할 수 있습니다.
특정 회사가 특정 목적을 위하여 자사의 제품에만 적용될 수 있는 반도체를 위탁하여 생산된 칩이 바로 ASIC 칩입니다.
마춤옷과 같이 회사의 제품 동작에 딱 맞는 기능만 들어가 있어 성능이 좋고 쓸데없는 기능이 들어가 있지 않아 군더더기로 인해 소모되는 에너지도 적습니다.
구글의 TPU는 바로 이런 ASIC 칩입니다.
다른 회사에서 팔라고 해도 굳이 팔아야 할 필요가 없습니다.
사가는 회사도 그 회사의 ASIC 칩을 어떻게 조립하고 또한 그것의 동작 원리도 알 수 없어 사용할 수가 없습니다.
구글 TPU의목적
머신러닝 워크로드를 빠르게 처리하는 데 사용됩니다.
구글이 머신러닝 분야에서 쌓은 오래된 경험과 그들만의 경쟁력을 바탕으로 설계 된 머신러닝 소프트웨어에 최적화된 ASIC 칩입니다.
구글 TPU 리소스는 머신러닝 소프트웨어에서 주로 사용 되는 선형대수(Linear Algebra) 연산 성능을 가속화합니다.

여기에서 선형대수란 행렬 곱하기 벡터 혹은 행렬 곱하기 행렬을 의미합니다.
주로 고등학교때 배우는 수학으로 다음과 같은 계산이 바로 행렬 곱하기 벡터입니다.
실제로 우리가 접하고 있는 머신러닝 인공지능 혹은 멋진 그림을 그려내는 생성형 AI 소프트웨어가 동작하는 기본 동작은 위의 선형대수 계산 작업을 수십만 혹은 수백만 번 계속하여 결과를 얻어 냅니다.
TPU를 사용하면 복잡한 대형 신경망 모델을 학습시킬 때 정확성 달성 시간을 최소화할 수 있습니다. 다른 하드웨어 플랫폼에서는 학습하는 데 몇 주가 걸렸던 모델이 TPU에서는 몇 시간이면 수렴 단계에 도달할 수 있습니다.
CPU GPU TPU를 사용한 계산 방법의 예
일반적인 CPU를 사용하는 경우


- 8이라는 숫자 하나를 인식하기 위하여 9쌍의 데이터와 모델을 일일이 메모리에서 불러와 계산하고 비교하는 일을
- 7,8,9 모델에 한번씩 수행하여 총 27번의 메모리 조작이 일어남을 볼 수 있습니다.
- 물론 이 계산을 1~9 전체 숫자와 비교하려면 9×9번 =81번의 조작을 수행하여야 합니다.
GPU를 사용하는 경우

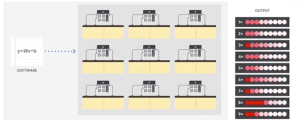
- GPU내부의 many core를 사용합니다.
- 총 9개의 core를 사용하여 각 core로 하여금 자기가 1번 core이면 1번 모델과 입력받은 숫자를 비교하고 2번 core이면 2번 모델, 이런 식으로 9개의 core가 총 1부터 9 모델을 입력받은 숫자 비교하는 작업을 동시에 수행합니다.
- CPU같으면 총 81번의 메모리 조작이 필요하지만 이경우 9개의 모델을 비교하여 결론을 내는데 9번의 메모리 조작만 하면 끝나게 됩니다!
TPU를 계산하는 경우






한번의 메모리 조작으로 5,6,7,8,9 모델을 한꺼번에 불러옵니다.
아울러 어떤 숫자인지 판별을 해야하는 샘플값(풀어야 할 문제)도 5개를 한번에 불러옵니다.
이 작업 한번으로 위의 CPU와 GPU가 전체적으로 5번의 반복을 해야 하는 작업을 한번에 끝낼 수 있게 됩니다.
더욱이 행렬계산 과정에서도 메모리를 조작할 필요가 없습니다.
왜냐하면 계산한 행과열의 곱의 합을 다음 TPU로 넘기면 최종 TPU에서 모든 계산 결과가 자동으로 합산 되기 때문입니다.
마치며
위의 예에서와 같이 구글의 TPU는 한번의 메모리 조작만으로 일반 CPU가 80회 이상의 메모리 조작을 해야 풀수 있는 문제를 동시 5개를 풀어냅니다.
삼성은 명실 상부한 세계 최고 하드웨어 반도체 회사입니다. 삼성에서도 구글및 NVIDIA에 필적할만한 좋은 삼성 AI 두뇌 차세대 칩 을 성공적으로 개발할 수 있기를 기원합니다.





