![A logo representing a calm, happy Sweden countryside village with only blue color palette [and has a minimalist and modern style] [incorporating elements of nature] [with a touch of Scandinavian design] [that reflects a sense of community]](https://raonstad.com/wp-content/uploads/2024/03/img-rsVXmvlyKd0umO7b2rMmaUnI.png)
트랜스포머 모델의 중요성 재조명하기 – 답변의 일관성
지난번 포스팅에서는 우리가 현업에서 사용하는 트랜스포머 모델들의 입력 프롬프트가 만들어지는 과정을 보았다.
아울러 전체 프롬프트를 기반으로 답이 생성되는 과정은 토큰이 하나씩 순차적으로 결정되는 과정이며 이러한 토큰의 생성은 모델이 훈련된 구성을 바탕으로 한 토큰씩 가장 확률이 높은 토큰을 생성해 내는 과정이라는 것을 다루었다.
그렇다면 의문점을 가질 수 있다. 구성된 정보의 순서 (연속된 토큰 들의 모임)에도 불구하고 왜 LLM의 답변은 매번 달라 지게 되는 것일까?
토큰 샘플링 (Token Sampling)
지난 번 포스팅에서는 모델이 자기회기 루프를 통하여 동작하는 원리를 알아 보았다. 매번 다음 토큰을 결정하기 위하여 모델은 전체 토큰에 대하여 확률 값을 계산한다. 그리고 선택한다.
예를 들어 생각해보자. 토큰 “A” 에 대한 확률이 0.13924 그리고 토큰 “B”에 대한 확률이 0.13926이다. 당신이라면 어떤 것을 선택 하겠는가?
엄밀하지는 않지만, 모델이 학습한 텍스트들에서는 A와 B가 비슷한 경우로 쓰이되 B가 A보다 0.000002 정도 자주 쓰인다는 것과 비슷하다. 그렇다고 B를 선택하는 것이 맞을까?

그리디 디코딩 (Greedy Decoding)
‘Greedy’라는 말은 탐욕스러운 이라는 뜻이다. 단순히 수학적으로 확률이 가장 높은 토큰을 다음 토큰으로 선택하는 방식이다. 가장 높은 확률의 토큰이 항상 선택되는 이유로 거의 변하지 않는다. 즉 결정론적(deterministic)이다.
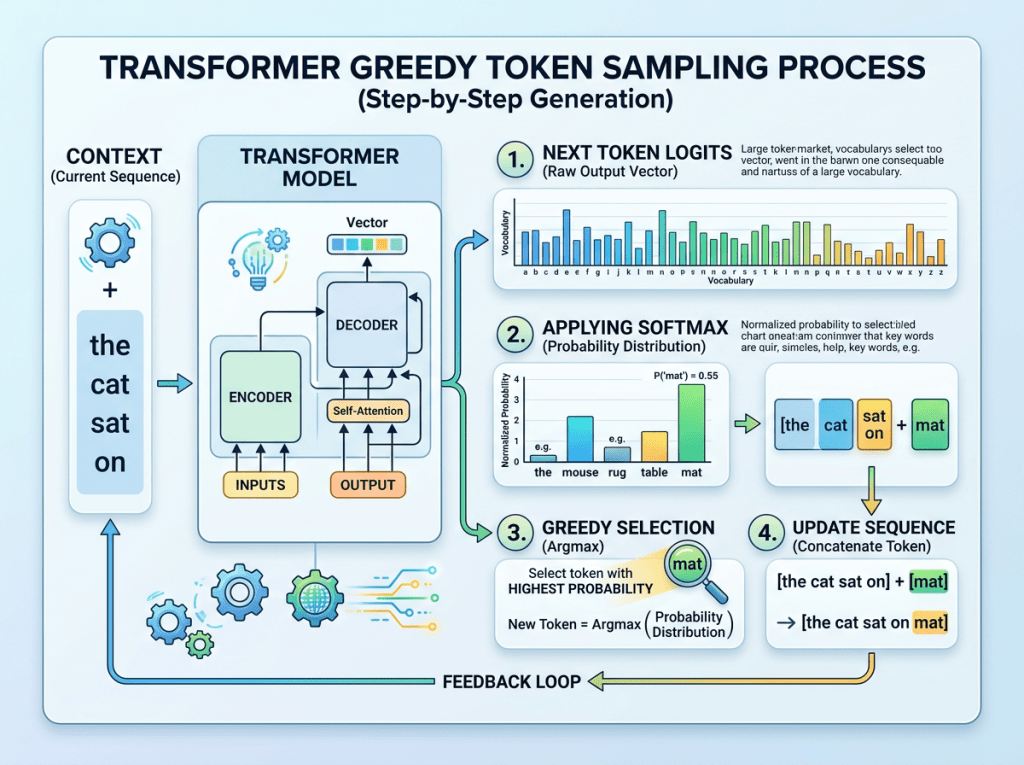
그러나 강의에서는 이것이 항상 좋은 선택은 아니라고 한다. 이유는 가장 가능성 높은 토큰만 계속 선택하면 출력이 다소 지루하고 틀에 박혀 보일 수 있다는 이유이기 때문이다.
또한 과거에는 이러한 선택 방식이 반복 루프를 발생 시키기도 했다고 한다. 사례는 궁금했지만 별 의미가 있을 것 같지 않아 추가 조사는 하지 않기로 했다.
랜덤 샘플링 (Random Sampling)
위의 경우는 가장 가능성 높은 토큰이 항상 선택되는 반면, 랜덤 샘플링 방식에서는 확률에 따라 가중치를 부여한다.
가중치가 부여 되었다는 이야기는 여러번 수행하면 가중치가 높은 토큰이 많이 발생된다는 이야기이다. 그러나 매 순간 그리디 디코딩처럼 토큰하나가 결정되지는 않는다.
무작위성이 들어가게 되면 인간의 창의성과 같은 창의적인 답을 얻을 확률이 높다. 주변에 창의적인 사람이 처음에는 엉뚱한 의견을 제안하는 것처럼 말이다.
다만 주의가 필요한 경우로 모든 토큰에서 샘플링하는 경우를 들 수 있다. 이경우에는 확률이 매우 낮은, 전혀 어울리지 않는 토큰이 선택될 수도 있고 이로 인하여 전체 결과가 이상해 질 수도 있다.
트랜스포머의 주요한 동작원리인 자기순환적인 구조를 생각하면 초반에 등장하는 이상한 토큰하나가 전체 답변의 방향을 괴상한 쪽으로 잡혀지게 될 수 있다.

온도 (Temperature)
과거 고등학교때 물리시간에 배운 “온도”라는 개념을 상기해 보자.
온도가 높으면 기체 분자의 운동에너지가 높고 온도가 낮으면 기체 분자의 운동에너지가 낮다라는 개념을 모두 알고 있을 것이다. 온도라는 것은 이러한 물리학의 온도 개념에서 가져온 개념이다.
전체 토큰들의 확률 분포를 바꿔서 특정 토큰을 더 또는 덜 선택하도록 조정하는 경향성을 결정하는 방식이다.
- 온도가 높을수록 확률 분포가 평탄해져 다양한 토큰이 선택될 확률이 높아진다. 가장 높은 확률의 토큰이 선택될 가능성이 평탄해지고, 확률의 분포가 토큰들에게 골고루 퍼지게 된다.
- 온도가 낮을수록(0에 가까울수록) 그리디 샘플링과 비슷하게, 가장 가능성 높은 토큰만 선택하게 된다.
Top-K
상위 K개의 토큰 중에서만 토큰 선택이 이루어 지는 방식이다.
- Top-K = 1: 가장 높은 확률의 토큰만 선택 (그리디와 동일)
- Top-K = 5: 확률 상위 5개 토큰 중에서 선택
어떤 프롬프트에서는 상위 5개 토큰이 모두 합리적인 선택일 수 있지만, 다른 경우에는 3번째 이하의 토큰들에 대한 선택 확률이 낮아지게 되면 모델의 동작이 엉뚱한 방향으로 진행될 수 있다.
Top-P (Nucleus Sampling)
P는 확률을 의미한다. 0~100%의 값을 설정하면, 이때 P는 누적 확률 질량(cumulative probability mass)을의미한다. 설정된 누적 확률 질량에 대응되는 토큰들에서만 샘플링이 이루어 진다.
주사위를 던져서 1 혹은 2 혹은 3 이 나는 각각의 확률은 모두 1/6 이다. 이 확률을 다시 “3” 이하가 나올 확률이라고 표현하면 전체 확률은 1/6+1/6+1/6 =0.5 이므로 50% 이다.
- Top-P = 100%: 모든 토큰에서 샘플링
- Top-P = 90%: 누적 확률이 90%에 도달하는 상위 토큰들에서만 샘플링
온도가 낮으면 분포가 뾰족해져 Top-P 90%가 소수의 토큰만 커버하게 된다. 반대로 온도가 높으면 분포가 평탄해져 같은 Top-P 90%라도 더 많은 토큰이 포함되는 구조이다.

마치며
위와 같이 LLM이 매 번 질의때마다 서로 다른 형태의 답변을 하게 되는 구조를 정리해 보았다.
중요한 점은 두가지로 요약 될 수 있다.
LLM의 답변은 모두 확률에 기반한 가장 있음직한 논리의 전개라는 사실이다. 입력으로 들어오는 정보를 기반으로 현재 토큰 선택 정책에 따라 최선의 확률 조합을 제시한다.
물론 이 와중에는 임의성이 개입할 수도 있다. 이러한 임의성을 인간의 창조적인 생각과정과 직접 연관 지을 수 는 없을 것으로 판단된다. 왜냐하면 인간의 창조적인 생각 과정 자체가 아직 과학적으로 설명될 수 없기 때문이다.
가장 확률이 높은 답을 얻기 위해서는 가장 좋은 정보를 가장 좋은 방식으로 입력해야 여기에서 나온 산출물도 좋아지게 된다. 즉 입력 문서 작업에서 게으름을 피우지 말자는 제안이다.
두번째는 검증 (Verification)의 필요성이다.
인간의 언어로 얻은 답변이나 논리적인 판단으로 LLM의 결과를 사용할 때 항상 검증해야 한다. 왜 그런 답변을 냈는지에 대한 설명과 근거를 같이 확인하는 습관이 중요하다.
아울러 코딩 에이전트의 경우에는 일반적으로 코드가 그냥 쏟아지게 된다. 항상 코드가 맞게 나왔는지 확인하고 왜 이결과가 최상인지 검증해야 한다. 물론 최고의 검증은 시험이다.
앞의 포스트에서 코딩 자체는 이제 병목이 아니라고 이야기 했다. 어떤 범위의 어떤 테스트를 얼마나 즉각적으로 수행할 수 있느냐가 앞으로 생산성을 좌우할 수 있는 주요 인자가 될 수 있을 것이다.